Data Masking
What is Data Masking?
Data Masking is a pivotal technique, also known as data obfuscation, data encryption, or data anonymization, designed to protect sensitive information by replacing, encrypting, or scrambling original data with fictitious or pseudonymous data. This digital veil ensures data privacy and security, rendering data unreadable while preserving functionality.
Masking data can be reversible or irreversible, depending on the technique used. For example, encryption can be reversible if the encryption key is available, allowing the original data to be restored. However, techniques like tokenization and anonymization may be irreversible since the original data is not retained.
Common Data Masking Approaches
- Static Data Masking: Static masking involves applying different masking techniques to sensitive data before it’s stored or transmitted, typically during data migration or database refreshes.
- Dynamic Data Masking: Refers to real-time masking applied to sensitive data as it’s accessed, often implemented in database systems to protect data without altering the underlying data.
- On-the-Fly Data Masking: It encompasses static and dynamic masking, referring to the application of masking techniques either permanently or in real-time as data is processed, transmitted, or accessed.
Different Data Masking Techniques
Enhancing enterprise security involves implementing various Data Masking techniques such as tokenization, encryption, anonymization, redaction, Format-Preserving Encryption (FPE), substitution, shuffling, noise addition, hashing, nulling, referential masking, partial data exposure, and data swizzling. These masking techniques are integral components that fortify data security protocols, ensuring a comprehensive and resilient defense against potential internal and external threats.

Different types of data masking techniques
Key Benefits of Data Masking
By obfuscating real data with realistic but fictitious information, masking enables organizations to mitigate external and internal threats, fortify enterprise security, unleash business value, enhance customer trust, and stringent data privacy regulations like GDPR, CCPA, PIPEDA, LGPD, DPDP, and industry privacy regulations like PCI DSS, GLBA, FedRAMP, FERPA, HIPAA, and among others. By maintaining data realism, masking allows for continued use in development, testing, and analytics, fostering innovation while preserving confidentiality.
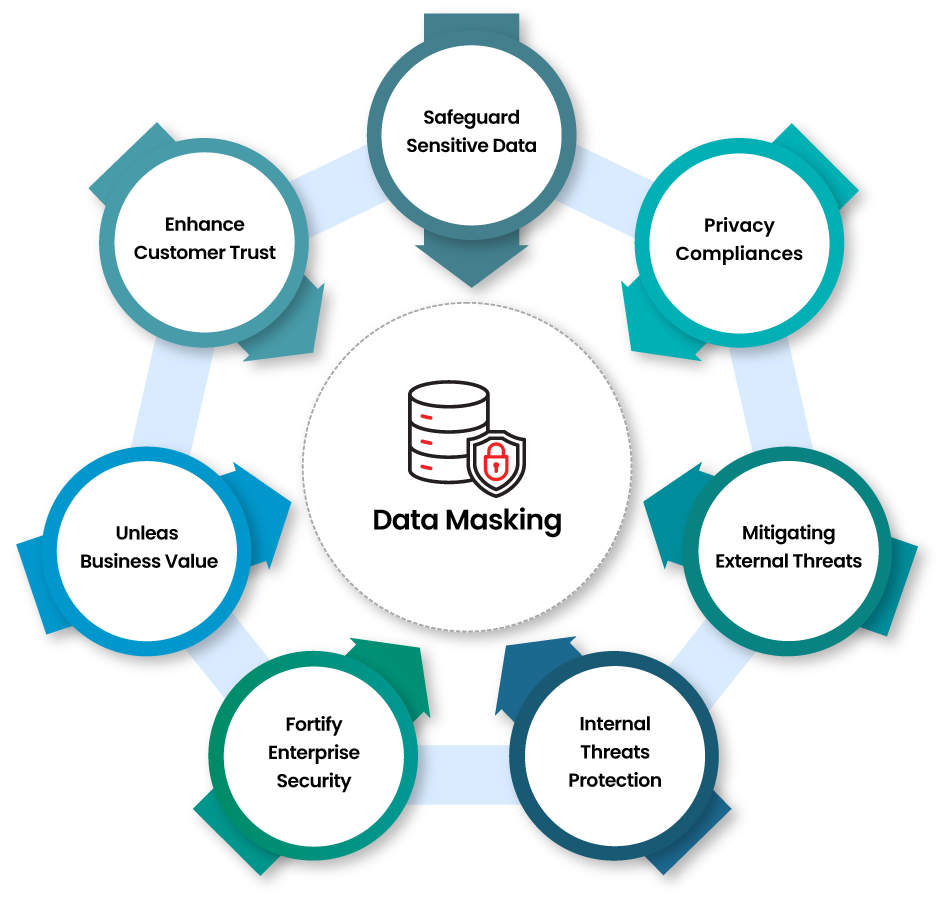
Key benefits of data masking
Use cases of Data Masking
Across industries, organizations utilize masking techniques to safeguard sensitive information in various scenarios. Here are a few instances where masking is used.
- Risk Mitigation: Minimize the impact of potential data breaches.
- Data Sharing: Share data subsets in a secure, compliant manner.
- Software Testing: Enable thorough testing without security breaches.
- Data Analytics and Reporting: Generate insights without compromising privacy.
- Compliance: Adhere to data protection regulations (GDPR, HIPAA, PCI-DSS, CCPA).
- User Training: Provide realistic training environments without sensitive data exposure.
- Collaborate with third parties: Maintain data control while collaborating with third parties.
- Test – Development Environments: Create datasets safely without exposing production data.
In conclusion, Data Masking is indispensable for protecting sensitive information without compromising data usability. By concealing confidential data with realistic yet fictitious substitutes, organizations can mitigate the risk of data breaches while ensuring compliance with stringent privacy regulations. Ultimately, It empowers businesses to securely share and utilize data for various purposes, safeguarding privacy and utility in today’s digital landscape.
FAQ
What is Data Masking?
Data Masking is a technique used to conceal sensitive information within a database, replacing it with fictitious but realistic data to protect confidentiality.
Is Data Masking reversible?
Data Masking can be reversible or irreversible based on the techniques used. For example, redaction is reversible, as it permanently masks the data, while techniques like encryption are reversible.
Can Data Masking be automated?
Yes, Data Masking can be automated using specialized software tools that streamline the masking process. Automation helps ensure consistency, scalability, and efficiency in masking techniques across large datasets and diverse environments.
Can data masking impact database performance?
Yes, data masking can impact database performance, particularly if complex masking algorithms are used or if the masking process is applied to large datasets. Performance considerations should be carefully evaluated during implementation.

Enter to win a $100 Amex Gift Card



