Data Shuffling
What is Data Shuffling?
Data Shuffling, also known as data permutation or swizzling, is a data masking technique that randomizes data records without altering content. Unlike data encryption or tokenization, it doesn’t rely on mathematical algorithms. Instead, it focuses on obfuscating the relationships between records, making it an ideal data security solution for preserving the statistical characteristics of the original dataset.
Data Shuffling is used on non-order-dependent data fields to maintain relationships and statistical characteristics, preserving data integrity. It is best suited for certain types of data, such as ZIP codes or dates, where the order of data is not critical. It may not be suitable for sensitive information, particularly when data connections must be preserved.
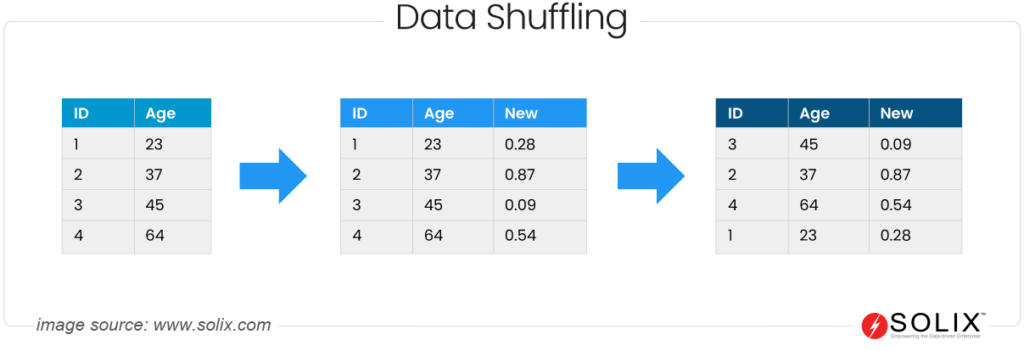
Pictorial representation of how Data Shuffling secures data
How Data Shuffling Secures Data?
Data Shuffling, a sophisticated data masking technique, operates by strategically rearranging the order of data records within a dataset, introducing a layer of randomness without modifying the actual content. Here is a brief view of how it secures data.
- Randomization Process: Shuffling initiates a randomization process where the positions of sensitive data elements are mixed within the dataset. This ensures that the order in which records appear becomes unpredictable, adding a dynamic layer of protection.
- Preservation of Data Structure: One key aspect is its ability to maintain the dataset’s structure. While the positions of individual records change, data relationships remain intact, preserving dependencies within the data and the original dataset’s integrity.
- Statistical Characteristics Preservation: It excels in preserving dataset statistics, which is crucial for accurate analytics. The shuffled dataset retains statistical relevance despite randomization, ensuring effective analytics and reporting.
Benefits of Data Shuffling
Data Shuffling, as a data masking technique, offers a range of compelling benefits that make it a valuable asset in ensuring data security, privacy, and regulatory compliance.
- Statistical Integrity: It retains data characteristics for analyses while ensuring accuracy and security in different environments. Organizations benefit from preserved statistical distribution and relationships, facilitating reliable data analysis on sensitive datasets.
- Enhanced Privacy and Compliance: Its dynamic masking approach protects sensitive data like personally identifiable information (PII) and financial records. It aligns organizations with different stringent data protection regulations.
- Internal – External Threat Mitigation: It adds a layer of complexity to data, reducing insider and external threats. Even with access, deciphering relationships is difficult, lowering the risk of intentional or unintentional data misuse within organizations.
- Balanced Anonymization: It helps balance anonymization and utility by concealing sensitive data while maintaining operational integrity for analysis. Ideal for industries like healthcare and finance, ensuring confidentiality while enabling critical data analysis.
Limitations of data swizzling
- Not suitable for all data types: Data swizzling is ineffective for masking certain kinds of data, such as dates, timestamps, or unique identifiers.
- Potential for reconstruction: Depending on the swizzling method used and the complexity of the data, it might be possible to reconstruct the original data with enough effort and computational power.
- May not comply with regulations: For some data privacy regulations, such as GDPR, data swizzling alone might not be sufficient to anonymize personal data.
Use Cases of Shuffling
Data Shuffle is a versatile data masking technique applicable across diverse scenarios. It provides robust solutions to secure sensitive information while preserving data functionality in non-production environments, production settings, and other contexts.
- Testing and Development Environments: It is instrumental in creating secure yet realistic datasets for testing and development purposes. Organizations can simulate real-world scenarios without compromising data privacy while adhering to data privacy requirements.
- Efficient Data Analysis and Reporting: It enables secure analysis, allowing organizations to derive insights from masked data. Analysts can confidently explore trends, patterns, and anomalies without compromising privacy, balancing data security and utility.
- Privacy-Preserving Data Sharing: By obscuring connections between records, entities can securely exchange information without revealing sensitive specifics, promoting collaboration without jeopardizing data security.
- Secure Analytics in Healthcare: It allows healthcare organizations to share datasets for research or analytics, ensuring that sensitive patient information remains protected through randomized record arrangements.
- Financial Data Analysis: It is suitable in the finance industry, where data analysis is critical for making informed decisions. Organizations can maintain confidentiality during analyses by masking sensitive financial data, ensuring a balance between data utility and protection.
- Preserving Relationships in Research: Research environments often demand diverse datasets with interconnections. Shuffled data preserves these relationships, ensuring accuracy while safeguarding identifiable information and maintaining integrity in research endeavors.
- Balanced Anonymization in Telecom: It aids telecommunication companies in balancing anonymization in large datasets. It helps them to protect customer information while facilitating practical network analysis and optimization.
- Secure Data Migration: Data swizzling is a valuable tool during data migration processes. It protects sensitive information, preserving structure and relationships crucial for seamless operations in the target environment.
In summary, Data Shuffling’s versatility extends to testing, analysis, collaborative data sharing, healthcare research, financial analytics, and various other scenarios. Its adaptive nature makes it a practical choice for organizations seeking comprehensive data masking solutions in diverse non-production environments. In the evolving landscape of data security and privacy, It stands out as a compelling data masking technique that balances the need for protection with the demands of analytical processes.
FAQs
How does data shuffling differ from other masking methods?
Unlike other masking methods like substitution or tokenization, data shuffling doesn’t replace data with a consistent value. Instead, it reorders records, making correlating original and masked data harder, thus enhancing security and privacy.
Is data shuffling reversible?
No, data shuffling is typically irreversible. Once data records are shuffled, the original order is lost, making it extremely difficult to reconstruct the original dataset. This irreversible nature enhances security by preventing unauthorized access to sensitive information.
Can data shuffling be combined with other masking techniques?
Data shuffling can be combined with other masking techniques, such as substitution and tokenization, to create layered security measures. Organizations can achieve comprehensive data protection by leveraging multiple masking methods while maintaining usability and compliance.
Is data shuffling suitable for all types of datasets?
While data shuffling is effective for many sensitive datasets, its suitability depends on specific use cases and data requirements. Organizations should evaluate data volume, complexity, and analytical needs before implementing data shuffling as a masking technique.

Enter to win a $100 Amex Gift Card



